
Cómo configurar Screaming Frog muy fácil
Si ya sabes para qué sirve Screaming Frog, comprenderás que la forma en la que lo configuremos es fundamental para rastrear solo lo que necesitamos. Por ello, en este artículo te explico como configuro yo este crawler en su versión más sencilla.
Aquí te dejo mi reseña de SE Ranking y un cupón para que puedas probarla GRATIS.

¡Aquí vamos al grano!


- Configuración de Screaming Frog
- Configuración del rastreo en Screaming Frog
- Configuración de la extracción en Screaming Frog
- Configuración de los límites en Screaming Frog
- Configuración del renderizado en Screaming Frog
- Configuración avanzada de Screaming Frog
- Configuración de las preferencias de Screaming Frog
- Otras configuraciones de Screaming Frog
- Guarda tu configuración
Configuración de Screaming Frog
Lo primero de todo, para configurar Screaming Frog debes ir a la barra superior y seleccionar Configuración > Configuración del rastreo.
En este momento verás que se abre una ventana enorme con un montón de configuraciones, de las cuales nos vamos a centrar en aquellas propias del spider:

Vamos a ver cada una ellas y cómo de importante son para mi:
- Rastreo (fundamental): En esta sección ajustamos los aspectos críticos del proceso de rastreo. Puedes decidir si quieres seguir o no los enlaces externos, rastrear subdominios, o cómo manejar las redirecciones. En resumen, en este modulo controlamos lo que Screaming Frog rastreará para nosotros.
- Extracción (fundamental): Aquí puedes configurar Screaming Frog para que extraiga información específica durante el rastreo, como datos de CSS, JavaScript, y enlaces. También podemos configurarlo para extraer datos personalizados mediante XPath, CSS Path, o regex, lo que es particularmente útil para análisis SEO avanzados y auditorías de contenido. Perfecto si necesitas extraer datos más allá de los elementos estándar de SEO.
- Límites: La sección de límites te permite definir los topes para el rastreo, lo cual es útil para evitar el consumo excesivo de recursos o para centrarse en áreas específicas de un sitio web. Puedes establecer límites en el número de rastreos, el tamaño máximo de descarga por archivo, o incluso el tiempo máximo de rastreo.
- Renderizado: El renderizado se refiere a cómo Screaming Frog interpreta las páginas web durante el rastreo. Puedes elegir entre rastreo basado en solo texto (el HTML, que va más rápido y es menos intensivo en recursos) o renderizado de JavaScript (necesario para sitios web que cargan contenido dinámicamente con JavaScript).
- Avanzado: Aquí podemos configurar aspectos más técnicos del rastreo, como ajustar el comportamiento de los robots.txt, configurar la identificación del agente de usuario, gestionar cookies, y establecer parámetros de seguimiento de sesión.
- Preferencias (interesante): En esta sección podemos ajustar configuraciones generales que afectan el funcionamiento global de la herramienta, incluyendo la configuración de memoria, cómo se guardan y se exportan los reportes, y las preferencias de visualización.
Vista cada una de ellas por encima vamos a profundizar en cada una.

Configuración del rastreo en Screaming Frog
De partida yo siempre configuro Screaming Frog de la siguiente forma:

Vamos a ver por qué:
Enlaces de recursos
- Imágenes: siempre marco las imágenes de una web porque me interesa obtener información sobre el atributo ALT HTML o su tamaño.
- CSS, Javascript y SWF: no lo marco porque no considero necesario en mis proyectos analizar estos recursos (especialmente los archivos flash)
Enlaces de páginas
- Enlaces internos: fundamental para controlar los enlaces entrantes de las URLs de tu web.
- Enlaces salientes: fundamental para controlar los enlaces que salen de las URLs de tu web.
- Canonicals: importante para mis proyectos, aunque más importante si tienes ecommerce de miles de URLs en los que canonicalizas URLs de productos.
- Paginación: mis webs no tienen paginaciones por lo que no lo marco pero si la tuya si tiene márcalas.
- Hreflang: márcala si tienes una web en varios idiomas.
- AMP: este sistema está en desuso y, de hecho, nunca he trabajado con webs en formato AMP.
- Meta refresh y iframes: no lo considero importante en mis proyectos.
Comportamiento del rastreo
- Comprobar enlaces fuera de la carpeta de inicio: lo marco por curarme en salud. Esto es básicamente que si incluyes la url ‘universoeducativo.cl/universidades’ como punto de inicio, comprobará los enlaces hacia ‘universoeducativo.cl/carreras’
- Rastrear fuera de la carpeta de inicio: igual que la anterior pero en lugar de comprobar los enlaces, los rastrea.
- Rastrear todos los subdominios: márcala solo si la web a rastrear tiene subdominios. Por ejemplo, si la web es universoeducativo.cl y tiene el subdominio becas.universoeducativo.cl.
- Seguir «nofollow» interno: para que el crawler siga los enlaces nofollow dentro de tu web.
- Seguir «nofollow» externo: para que el crawler siga los enlaces nofollow que salen de tu web.
Sitemaps XML
- Rastrear sitemaps XML enlazados: fundamental para que rastree tu sitio web completo y detecte urls interesantes, como las huérfanas.
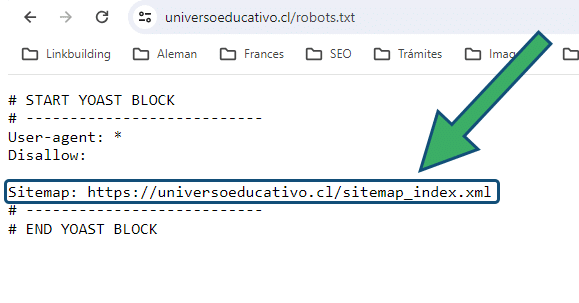
- Descubrir automáticamente sitemaps XML mediante robots.txt: para que detecte el sitemap a través del robot.txt
Ésto último es porque el sitemap está referenciado desde el robot.txt:

Configuración de la extracción en Screaming Frog
La extracción la configuro de la siguiente forma:

Detalles de la página
Yo marco todo, aunque es cierto que podemos dejar fuera el valor del hash o la proporción de texto y código.
Detalles de URL
- Tiempo de respuesta y última modificación: aunque aquí he de decir que para el tiempo de respuesta, prefiero configurar la API de Page Speed (lo veremos más adelante en el curso).
Directivas
- Meta robots: para extraer el contenido de esta meta.
- X-Robot-Tag: para extraer el encabezado del X-Robot-Tag.
Datos estructurados
- JSON-LD: para analizar los datos estructurados.
- Microdatos: para analizar sus microdatos.
- RDFa: para analizarlos datos en este formato.
- Validación de Schema.org: para comprobar si los datos estructurados están bien implementados.
HTML
No lo toco.
No lo toco.

Te enseño a auditar tu web con Screaming Frog, para que identifiques y soluciones los problemas que están afectando tu SEO.
¡Comienza mi curso de Screaming Frog gratis hoy!
Configuración de los límites en Screaming Frog
La configuración que viene por defecto en este sentido está correcta y, salvo que tengas una web monstruosa, no es necesario que toques nada.

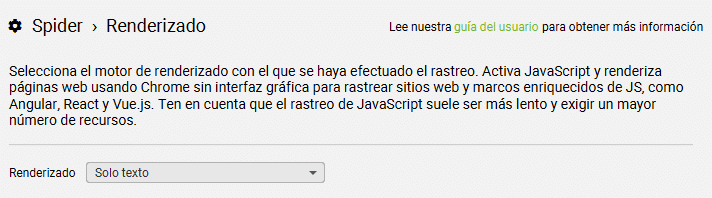
Configuración del renderizado en Screaming Frog
Marca el renderizado de "Solo texto" para extraer exclusivamente el HTML (salvo que tu web cargue dinámicamente contenidos con JavaScript).
Configuración avanzada de Screaming Frog
Yo lo dejo tal cual está.

- Ignorar URL no indexables en los problemas: lo marco porque si una URL no es indexable «me da igual» si tiene problemas.
- Ignorar URLs de paginación para filtros duplicados: esto es útil si tienes paginaciones. Yo no las tengo, por lo que no me afecta pero tampoco voy a ir expresamente a desmarcar esta opción por ello.
- Efectuar validación HTML: analizar errores que tengamos en el código HTML. Me parece muy útil si estamos tocando el código en la BBDD, por ejemplo.
Configuración de las preferencias de Screaming Frog
De entrada lo puedes dejar tal y como está por defecto, pero dependiendo de tu proyecto quizá quieras modificar algunos puntos.

A lo que voy con el punto antes comentado es que si tienes una web de nicho, el límite para considerar una imagen como pesada está bien en su valor por defecto (100 KB). En cambio, si llevas la web de un fotógrafo quizá tengas que subir este límite.
En resumen, si no te quieres complicar la vida, déjalo como está y si tienes algún proyecto más complejo échale un vistazo.
Otras configuraciones de Screaming Frog
Además de todo lo anteriormente comentado existen otros aspectos que puedes configurar. Aquí te explico algunos de ellos.
Configuración de la velocidad de rastreo
La editas desde Contenido > Velocidad. Aquí mi consejo es que si tienes un servidor VPS potente y una web grande, subas el número máximo de hilos hasta 10 o 20.

En cambio, si tienes un hosting compartido básico, es probable que te empiece a dar errores 503 en el rastreo por lo que te aconsejo reducir este número a 3 y además limitar el número de URLs a 1.
Configuración del User Agent
Esta opción te permite elegir el bot con el que rastrear la web. Por defecto, el elegido es el propio de Screaming Frog, pero lo puedes cambiar por varios motivos.
El primero es que hay proveedores como WebEmpresa (o alguna competidor en su web) que lo capan y no te permiten rastrear la web. Ante esto, bien puedes forzar ese acceso o puedes cambiar el bot directamente.
La segunda es que si quieres hacer un rastreo de tu web similar al de Google, puedes usar Search Console para sacar el bot que ha usado y ponerlo tu (como ves arriba).

Configuración de la memoria
Si vas a configurar webs tremendamente grandes, puedes modificar la asignación de memoria que le das a Screming Frog. Por defecto, está seteado con 4 gigas, que está muy bien, pero si ves que va lento el rastreo, páusalo y ve a Archivo > Configuración > Asignación de memoria para aumentarlo a 8 GB, por ejemplo.

Análisis de rastreo
Aunque, de entrada, esto no es una configuración como tal, te aconsejo leerlo si quieres ver el page rank de tu web (link score en Screaming Frog).
Para conocer el PR de tu sitio, una vez terminado el rastreo puedes ir a Análisis de rastreo > Configuración y marcas la opción de Link Score.
Tras ello le das a comenzar y en pocos segundos vas a tener esa métrica en tu análisis.
Pues bien, si te fijas en la imagen de abajo, ahora existe la opción de que se haga automáticamente al final del rastreo con el check box que aparece abajo. Márcalo y olvídate de hacerlo manualmente al final.

Guarda tu configuración
Una vez hayamos terminado con la configuración de Screaming Frog, guárdala para no tener que estar rehaciéndola cada vez que vayas a rastrear un proyecto.
Para ello, ve a Configuración > Perfiles > Guardar.

Cargar tu configuración
De igual forma, para cargar la configuración establecida en Screaming Frog, solo tienes que ir a Configuración > Perfiles y cargar la que hayas guardado.
Y con esto ya hemos terminado el tutorial sobre la configuración de Screming Frog. Espero que ya tengas tu rana lista para analizar tu web. ¡Vamos con ello!

Si has llegado hasta aquí… ¡Apúntate a mi Newsletter y sigue aprendiendo cada semana sobre SEO!
Deja una respuesta