
Tutorial de XPath
En este tutorial de XPath te voy a explicar todo lo que sé sobre este lenguaje y cómo lo uso en mi día a día para scrapear y extraer datos de páginas webs. Aunque está enfocado hacia el SEO realmente puedes aplicarlo para tus desarrollos en Python, Java o cualquier herramienta de desarrollo que uses.
Qué es XPath
XPath, que significa XML Path Language, es un lenguaje que se utiliza para navegar a través de elementos y atributos en documentos XML con la idea de extraer información.
Aquí te dejo mi reseña de SE Ranking y un cupón para que puedas probarla GRATIS.

Si sigues sin comprenderlo, no te preocupes porque las definiciones dan igual, lo importante es saber para qué sirve y cómo empezar a aplicarlo.
Para qué sirve y qué podemos extraer
Gracias a XPath podemos scrapear información de archivos XML y HTML a través de herramientas como Screaming Frog, Octoparse o Google Sheets con la idea de extraer información como la siguiente:
- Títulos de página (
<title>) - Encabezados (
<h1>,<h2>, etc.) - Metaetiquetas (description, robots, etc.)
- URLs e hipervínculos (
<a href="">) - Imágenes (src, alt)
- Precios
- Nombres de productos o servicios
- Reseñas o valoraciones
- Descripciones de productos
- Fechas (de publicación, actualización, etc.)
- Breadcrumbs o migas de pan
- Datos estructurados (Schema.org)
- …

Ejemplo de XPath para SEO
Vamos a empezar ya a bajar un poco al barro y vamos a ver un par de ejemplos de expresiones con XPath. Para ello, tomaremos como ejemplo la página de SEO para principiantes y vamos a ver como podríamos extraer el elemento H1:
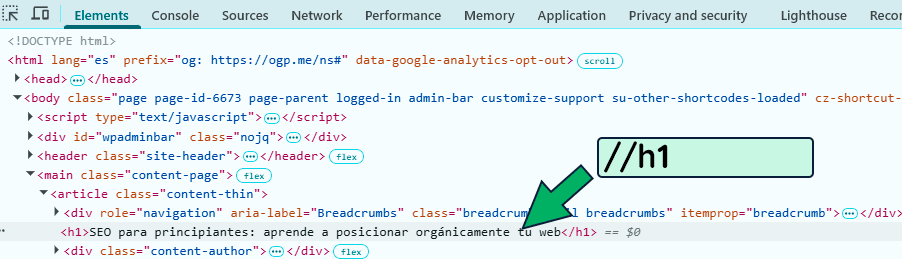
Aunque ya lo ves en la image, para extraer el h1 debemos usar la expresión //h1.
¿Y por qué la expresión //h1?
Te explico:
-
//le dice a XPath que busque en cualquier parte del documento. -
h1es el nombre del elemento que estás buscando.
Pero eso no es todo, ya que para obtener dicho header también podemos seguir la estructura jerárquica hasta llegar a nuestro elemento. Y para ello, debemos partir desde la raíz (el elemento HTML) y empezar a descender por todo el árbol de nodos.
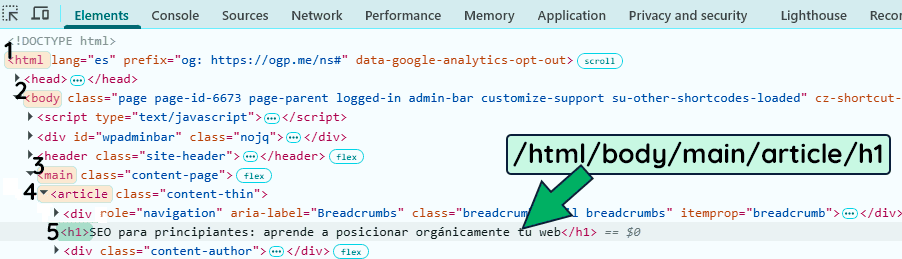
Así pues y como ves abajo, la expresión alternativa sería:
/html/body/main/article/h1De hecho podemos hilar más fino ya que la expresión //h1 devuelve el elemento HTML completo, es decir, lo de abajo:
<h1 class="titulo">Guía completa de SEO</h1>Y si yo quiero solo el texto debo especificar a continuación la función text(). Así pues, la expresión final quedaría como te muestro abajo:
//h1/text()Y el resultado sería:
Guía completa de SEO
Por supuesto, esto aplica también a la expresión /html/body/main/article/h1, donde podemos cambiarla por /html/body/main/article/h1/text() para extraer puramente el texto.

Diferencia entre expresiones XPath absolutas y relativas
Como hemos visto en la sección anterior, existen 2 tipo de expresiones de XPath con las que podemos extraer información de una página web.
- XPath absoluto: expresión que parte desde el inicio del documento, o sea, desde la raíz del HTML (
<html>), y sigue una ruta exacta hasta el elemento que quieres. Ejemplo: /html/body/main/article/h1 - XPath relativo: expresión que parte desde cualquier parte del documento y busca el elemento que necesitas sin depender de toda la estructura. Ejemplo: //h1
¿Cuál deberías usar? La que te funcione y te sea más cómoda. Ninguna es mejor que la otra.

Te enseño a auditar tu web con Screaming Frog, para que identifiques y soluciones los problemas que están afectando tu SEO.
¡Comienza mi curso de Screaming Frog gratis hoy!
Atributos en XPath
Ahora que ya sabemos extraer el H1 vamos a extraer el título (<title>) y meta description. Te muestro abajo el código HTML por si te animas a practicarlo antes de ver el resultado:

Como imaginarás, el title sigue la expresión //title/text(), muy similar al ejemplo visto con el H1. En cambio, la metadescription se obtiene en base a la expresión de abajo:
//meta[@name='description']/@content¿Qué ha pasado?
Bueno pues la diferencia está en que el title es una etiqueta HTML mientras que el description es un valor de la etiqueta meta (fíjate en el código fuente). Así pues debemos crear una expresión que traiga la etiqueta meta, cuyo atributo sea name con valor description. Y una vez extraído, nos quedamos con su contenido (content).
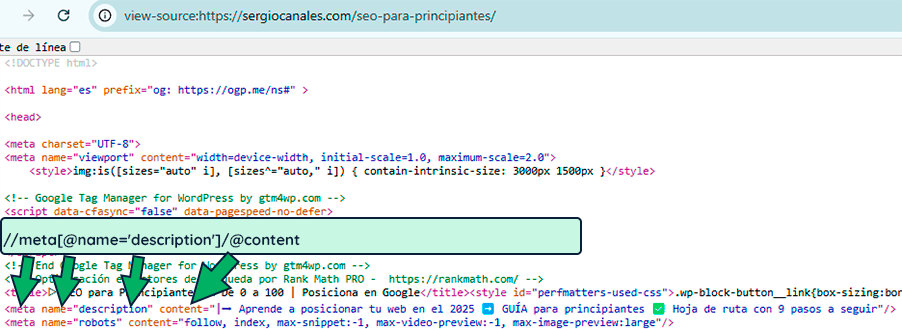
Esto me da pie a explicarte qué son los atributos.
class, id, href, src, etc.) son clave para identificar elementos específicos en un árbol HTML y/o poder filtrar para extraer específicamente lo que queramos.Para especificar un atributo debemos usar el símbolo de la arroba @.
Por ejemplo, si queremos extraer la url de un enlace en HTML debemos usar la expresión.
//a/@hrefEsto es porque la estructura de un link es la siguiente:
<a href="URL">Texto del enlace</a>Así mismo, para filtrar por un atributo debemos colocarlo entre corchetes y usando el símbolo de la arroba @.
Por lo tanto, si queremos filtrar o especificar que queremos el anchor text del enlace que apunta a la url https://sergiocanales.com/seo-para-principiantes/ debemos escribir la siguiente expresión.
//a[@href='https://sergiocanales.com/seo-para-principiantes/']/text()Esto es porque el enlace sigue la siguiente estructura:
<a href="https://sergiocanales.com/seo-para-principiantes/">aprender SEO desde cero</a>Sintaxis Xpath
En lo que al lenguaje de XPath se refiere existen una serie de elementos, que debes conocer para poder scrapear al máximo una web:
| Elemento | ¿Qué es? | Ejemplo | ¿Para qué sirve? |
|---|---|---|---|
| Nodos | Elementos del árbol del DOM: etiquetas (<div>, <a>, <p>), atributos, texto, comentarios, etc. | //h1 | Seleccionar elementos concretos dentro del HTML. |
| Predicados | Son condiciones que se colocan entre [] para filtrar resultados. | //a[@href='/contacto'] | Refinar búsquedas para obtener nodos que cumplan ciertos criterios. |
| Ejes | Definen la relación entre nodos: padre, hijo, hermano, etc. | child::div, ancestor::body | Navegar el DOM de forma estructurada según jerarquía. |
| Funciones | Comandos integrados que permiten operaciones sobre los nodos o sus atributos. | contains(text(),'SEO') | Filtrar por texto parcial, contar nodos, convertir valores, etc. |
| Operadores | Símbolos que permiten combinar condiciones o realizar comparaciones. | =, !=, and, or, <, > | Hacer queries más complejas y específicas. |
Aunque quizá la tabla de arriba te sobrepasa un poco, te comento que 2 de los 5 elementos ya los conoces. Y es que, ya hemos hecho ejercicios con nodos (al extraer elementos como el h1 o el title) y hemos hecho un ejercicio con predicados (al filtrar por el atributo para extraer el meta description).
No obstante, vamos a profundizar un poco más en el maravilloso mundo de los predicados.
Predicados
Los predicados son condiciones que colocamos entre [] para filtrar resultados. Para comprenderlo bien, vamos a extraer las migas de pan de la página en la que hablo de la herramienta Vuela.
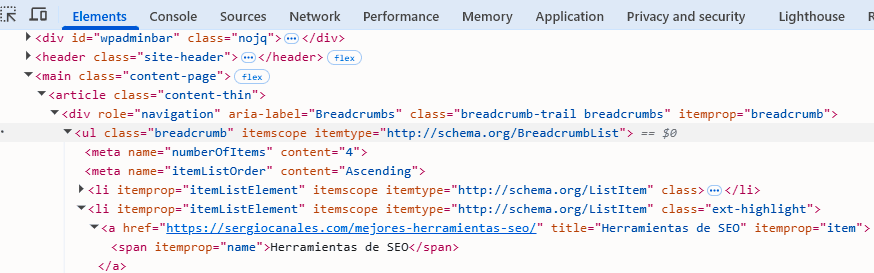
La expresión aquí sería:
//ul[@class='breadcrumb']/liEsto es así porque queremos extraer el elemento ul que contenga la clase breadcrumb (migas de pan). Y dentro de dicho nodo, nos queremos quedar con cada uno de los elementos listados.
Ahora, ¿Y si quisiéramos extraer simplemente el segundo elemento?
Lo especificaríamos con el predicado [2] a continuación de nuestra expresión:

Perfecto, vamos aún más lejos ¿Y si ahora quisiera el último o el segundo por el final (también llamado penúltimo en algunas culturas)?
En este caso usaríamos:
- //ul[@class=’breadcrumb’]/li[last()] para extraer el últmo
- //ul[@class=’breadcrumb’]/li[last()-1] para extraer el penúltimo.
Ejes
Un eje nos indica desde qué punto y hacia qué dirección estámos navegando dentro del árbol del DOM.
Lo vemos mejor con un ejemplo. Imagina que tenemos el HTML de abajo:
<div class="curso">
<h2>Curso de Screaming Frog</h2>
<p class="precio">60 €</p>
</div>Si quisiéramos sacar al elemento que está por encima del párrafo del precio, usaríamos la expresión:
//p[@class='precio']/parent::divEs decir, partimos del elemento que conocemos (el párrafo del precio) y subimos un nivel. Esto es útil ya que imagínate que queremos, por ejemplo, sacar el H2 que acompaña a cada precio, podríamos usar la expresión de abajo:
//p[@class='precio']/preceding-sibling::h2Funciones
El ejercicio anterior que hemos visto para sacar los H2 que acompañan a los precios está bien pero ¿y si quisiéramos sacar el número de elementos h2? Es ahí donde entran en juego las funciones.
Y como son unas cuantas las funciones, vamos a verlo paso a paso.
1. text()
Extrae el texto de un nodo. Por ejemplo
//h1/text()
Como resultado, devuelve el texto dentro del <h1>. Aunque esta ya la sabías.
2. contains()
Verifica si un nodo o atributo contiene una cadena parcial.
//a[contains(@href, 'blog')]
Encuentra todos los enlaces que contengan “blog” en su href.
Esta expresión me parece super interesante y te lo demuestro con un ejemplo. Imagina que tienes una página con muchos enlaces y quieres extraer aquellos que contenga la clase link1 y link2.
Si usamos //a[@class="link2"] solo devuelve el enlace con clase link2.
Y si usamos //a[@class="link1"] devuelve solo el enlace con clase link1.
No obstante, si aplicamos la expresión //a[contains(@class, "link")] nos devuelve los 2.
3. starts-with()
Selecciona nodos cuyo valor empieza con cierto texto.
//div[starts-with(@class, 'content')]
Encuentra divs con clases que empiecen por “content”.
4. normalize-space()
Elimina espacios innecesarios (iniciales, finales y dobles).
//h2[normalize-space(text())='Guía SEO']
Útil para igualar textos sin preocuparte por los espacios mal puestos.
5. position()
Se usan para ubicar nodos por orden.
//ul/li[position()=2]6. count()
Cuenta el número de nodos que coinciden con una condición.
count(//h2)
Devuelve cuántos <h2> hay en la página. Con esto, de hecho, resolvemos el misterio planteado anteriormente.
Operadores
Los operadores en XPath nos permiten crear expresiones más potentes combinando condiciones, haciendo comparaciones o filtrando elementos por posición o contenido. Básicamente, son como conectores lógicos y matemáticos dentro de las queries.
| Operador | Significado | Ejemplo |
|---|---|---|
= | Igual | //meta[@name='description'] |
!= | Distinto | //a[@rel!='nofollow'] |
< | Menor que | //li[position()<3] |
> | Mayor que | //li[position()>1] |
<= | Menor o igual que | //li[position()<=5] |
>= | Mayor o igual que | //li[position()>=2] |
and | Y (ambas condiciones verdaderas) | //a[@href and @title] |
or | O (una u otra condición verdadera) | //img[@alt='logo' or @class='logo'] |
Expresiones XPath útiles para SEO
Llegados a este punto ya eres todo un especialista en crear expresiones XPath para SEO pero para agilizarte la tarea de scrapeo, voy a dejarte una tabla con los comandos XPath que más uso en mi día a día.
| Expresión XPath | Qué extrae |
|---|---|
//title/text() | El título de la página |
//meta[@name='description']/@content | La meta descripción |
//h1/text() | El encabezado H1 principal |
//h2/text() | Todos los encabezados H2 |
//a[starts-with(@href, '/')]/@href | Enlaces internos relativos |
//a[starts-with(@href, 'http') and not(contains(@href, 'tusitio.com'))]/@href | Enlaces externos |
//img[not(@alt)] | Imágenes sin atributo alt |
//link[@rel='canonical']/@href | URL canónica declarada |
//meta[@name='robots']/@content | Valor de la metaetiqueta robots |
//span[@class='precio']/text() | Precio de un producto (ajustable por clase) |
//a[@rel='nofollow']/@href | Enlaces con atributo nofollow |
//script/@src | URLs de scripts cargados (útil para rendimiento) |
//ul[@class='breadcrumb']/li[2]/text() | Segundo elemento de breadcrumbs |
//h1[contains(text(),'SEO')] | H1 que contenga la palabra "SEO" |
//p[@class='precio']/preceding-sibling::h2/text() | Título asociado al precio (usando ejes) |
Si alguna expresión no te funciona puede ser porque tengas algún atributo o similar especificado en tu código. Pero no pasa nada, ya que a estas alturas eres capaz de identificarlo y corregirlo.
Herramientas de Xpath
En mi humilde opinión, la mejor herramienta que hay para probar nuestras expresiones es XPath Tester. Ésta es una extensión de chrome para SEO que nos permite verificar en tiempo real si nuestra expresión es correcta o no.
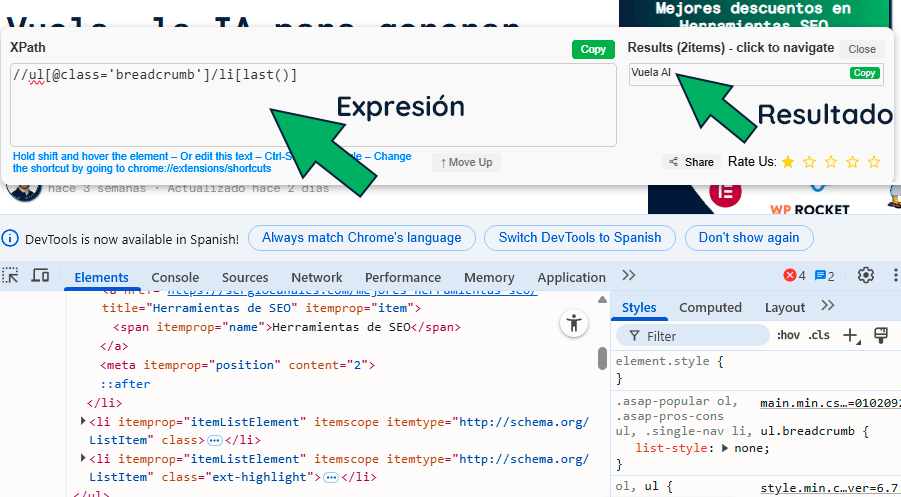
Así mismo, cuando inspeccionamos el código de nuestra web pulsando la tecla F12, podemos extraer la expresión XPath si hacemos clic en el elemento y vamos a Copy > Copy XPath o Copy full XPath.
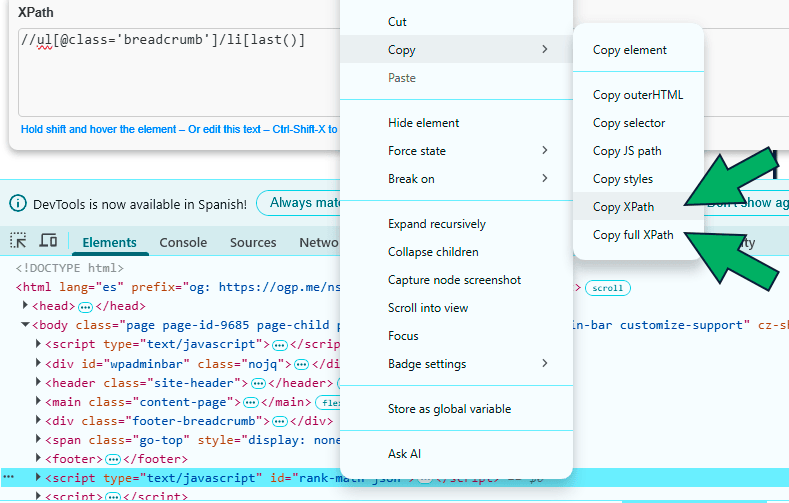
Dicho esto, ya te avanzo que el Xpath generado desde el inspector a veces no es demasiado específico y no podemos aplicarlo para un scrapeo en toda una web por lo que te aconsejo validar la expresión con la extensión que antes te he mencionado.
Aplicación a Screaming Frog
No voy a profundizar demasiado en este aspecto ya que en su momento escribí un artículo explicando cómo hacer custom extraction en Screaming Frog. Pero te comento que podemos aplicar XPath en esta herramienta a través de las expresiones personalizadas (desde Configuración > Personalizado > Extracción personalizada).

Así pues, imagina que tienes una página web con una ficha que contiene una dirección, teléfono e imagen, y queremos extraer estos datos. Para hacer esto, debemos analizar el elemento HTML que contiene dicha información y con el botón secundario > copy > copy Xpath obtendríamos su expresión (aunque recuerda validarla con la extensión XPath Tester).

Como siempre están en la misma posición, podemos crear una función como la que ves abajo:

Y después de ejecutar la herramienta encontraremos la información que queríamos en la pestaña de extracción personalizada.

Por cierto, si al ejecutar xpath en Screaming frog te devuelve un montón de resultados, prueba a envolver la expresión en (expresión)[1] para que te de el primero, que suele ser el que quieres.
Aplicación a Google Sheets
Además de Screaming Frog podemos usar Google Sheets para scrapear información de una web. Por ejemplo, en su momento ya expliqué cómo hacer una web sobre códigos postales en base a tablas scrapeadas con el comando IMPORTXML.
Y es que con este comando, basta con especificar una url y un xpath para extraer lo que queramos de una web.
Por ejemplo, en blog de SEO (cuya URL es https://sergiocanales.com/blog-de-seo/) podemos usar las siguientes expresiones para extraer la información que queramos.
| Elemento | Fórmula en Google Sheets |
|---|---|
| Título (title) | =IMPORTXML("https://sergiocanales.com/blog-de-seo/", "//title") |
| Meta description | =IMPORTXML("https://sergiocanales.com/blog-de-seo/", "//meta[@name='description']/@content") |
| H1 principal | =IMPORTXML("https://sergiocanales.com/blog-de-seo/", "//h1") |
| H2 (todos) | =IMPORTXML("https://sergiocanales.com/blog-de-seo/", "//h2") |
| Primer párrafo | =IMPORTXML("https://sergiocanales.com/blog-de-seo/", "//div[@class='the-content']/p[1]") |
Y el resultado sería el siguiente:

Por cierto, si hubiera una tabla y la quisiéramos screapear usaríamos el comando:
=IMPORTXML("https://ejemplo.com", "//table")
Si has llegado hasta aquí… ¡Apúntate a mi Newsletter y sigue aprendiendo cada semana sobre SEO!